I-SOON Leak Analysis using Python and Generative AI¶
Introduction¶
Analyzing leaked data can be a tedious task, especially if it's written in a foreign language. Luckily, with Python, it's possible to rapidly automate this process.
In the following notebook, we will analyze the data leak from I-Soon that provides sensitive information about potential Chinese espionage capabilities. This data leak is an interesting use case as most of the data are PNG files that require the use of OCR to automate the process of extraction. The leak is available here: https://github.com/I-S00N/I-S00N
The leak contains txt, logs, md and png files. This notebook will focus on the PNG file that represents the most amount of data.
The goal of this notebook is to provide the tools and workflow to let you analyze this kind of data by yourself.
Let's dive deep.
Disclaimer¶
Please use the data available in this notebook "as is". This document outlines a methodology for analyzing this kind of data and should not be considered an intelligence report.
The output provided may require additional verification due to possible inaccuracies in the translation or limitations inherent to LLM technologies.
Nevertheless, this document provides an initial step for analyzing leaked data, particularly PNG files in a foreign language.
Requirements¶
#!pip install Pillow pytesseract
#!pip install googletrans # Be carefull you might have some issue with the version of HTTPX use in this lib and OpenAI
#!pip install openai
#!pip install bokeh
# You also need an OpenAi API key
api_key = "sk-"
Analyzing the data¶
As always, the first thing to do before jumping into the data is to spend time understanding what kind of information we have, the structure, the format, the number of documents...
This is a crucial step to ensure you analyze your data in the right way. As we focus on the PNG file let's count how many we have in the repository.
import os
from collections import Counter
# Passing the directory
image_directory = '0'
files = os.listdir(image_directory)
# Extracting file extensions and counting occurrences
file_extensions = [os.path.splitext(file)[1] for file in files]
extensions_count = Counter(file_extensions)
# Printing statistics about file types
print("File Type numbers:")
for ext, count in extensions_count.items():
print(f"{ext if ext else 'No Extension'}: {count}")
Let's create a bar and pie chart to visualize the repartition.
from bokeh.io import output_notebook, show
from bokeh.plotting import figure
from bokeh.transform import cumsum
from bokeh.models import ColumnDataSource, HoverTool
from math import pi
import pandas as pd
output_notebook()
file_type_counts = {'png': 489, 'md': 70, 'log': 6, 'txt': 11, 'other': 1}
data = pd.Series(file_type_counts).reset_index(name='value').rename(columns={'index': 'file_type'})
data['angle'] = data['value']/data['value'].sum() * 2*pi
data['color'] = ['#0999d3', '#718dbf', '#e84d60', '#ddb7b1', '#ddb777']
# Pie chart
p = figure(height=350, title="File Type Distribution", toolbar_location=None,
tools="hover", tooltips="@file_type: @value", x_range=(-0.5, 1.0))
p.wedge(x=0, y=1, radius=0.4,
start_angle=cumsum('angle', include_zero=True), end_angle=cumsum('angle'),
line_color="white", fill_color='color', legend_field='file_type', source=data)
p.axis.axis_label = None
p.axis.visible = False
p.grid.grid_line_color = None
show(p)
from bokeh.io import output_notebook, show
from bokeh.plotting import figure
from bokeh.models import ColumnDataSource
import pandas as pd
output_notebook()
data = pd.DataFrame(list(file_type_counts.items()), columns=['file_type', 'count'])
# Convert DataFrame
source = ColumnDataSource(data)
# Create figure
p = figure(x_range=data['file_type'], plot_height=250, title="File Type Distribution",
toolbar_location=None, tools="")
# Add vertical bars
p.vbar(x='file_type', top='count', width=0.9, source=source, legend_field="file_type")
# Set attributes
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.yaxis.axis_label = "Count"
p.xaxis.axis_label = "File Type"
p.legend.orientation = "horizontal"
p.legend.location = "top_center"
# Display the plot
show(p)
To give you an example of what kind of information are available let's take a look to one of the image.
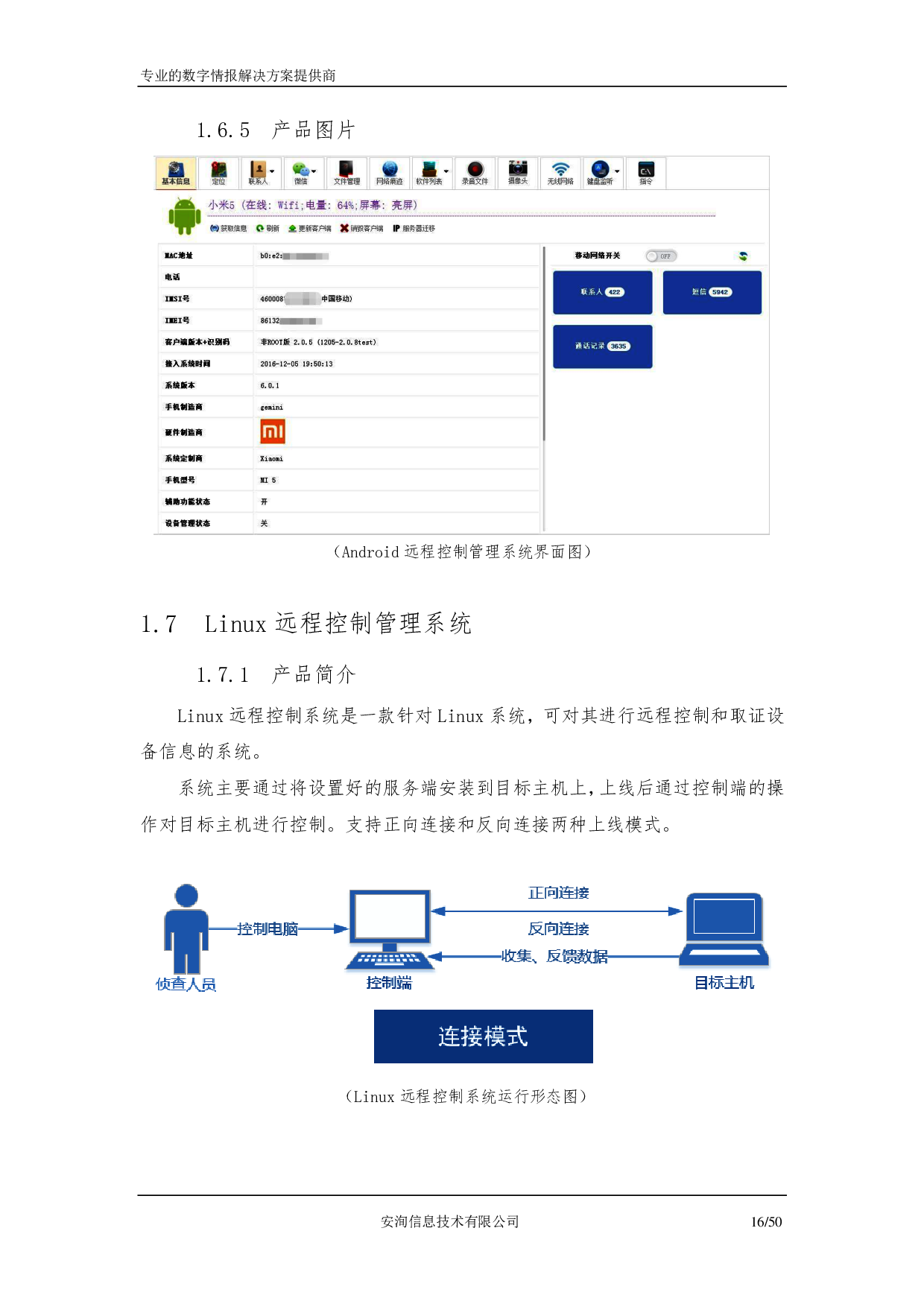
Here it is quite interesting because we have a screenshot that contains text, images and also diagrams. In other images we have screenshots of discussion or screenshot of Windows folders. Which makes a bit more difficult to analyze with context. And that will require an additional analysis. But let's focus here of extracting the text from our images.
Extracting and translating text for one image¶
Now that we have a better repartition and that we know a little bit better the content of the data, we are going to extract the text using OCR.
import os
# Set the TESSDATA_PREFIX
os.environ['TESSDATA_PREFIX'] = 'tessdata-main'
Analyzing one image at a time¶
from PIL import Image
import pytesseract
from googletrans import Translator, LANGUAGES
# Load the PNG image
image_path = '0/12756724-394c-4576-b373-7c53f1abbd94_15.png'
image = Image.open(image_path)
# Use Tesseract to do OCR on the image
text = pytesseract.image_to_string(image, lang='chi_sim') # 'chi_sim' for simplified Chinese
print("Extracted Text:", text)
# Translate in English
translator = Translator()
translated_text = translator.translate(text, dest='en')
print("Translated Text:", translated_text.text)
And now we have the image above translated! You can do it for a specific image by changing the path of the image, in the code above.
Processing the Image and storing them in a json file¶
So now let's automate the process of extraction and create a JSON file to request and access the data.
import os
import json
from PIL import Image
import pytesseract
from googletrans import Translator
# Directory containing PNG files
image_directory = '0'
# Sorting the file to keep track of the context when possible
files = sorted(os.listdir(image_directory))
translator = Translator()
results = []
for file_name in files:
# Check if the file is a PNG
if file_name.endswith('.png'):
file_path = os.path.join(image_directory, file_name)
# Perform OCR using Tesseract
image = Image.open(file_path)
text = pytesseract.image_to_string(image, lang='chi_sim') # Adjust lang as needed
if text and not text.isspace():
print(f"Extracted Text from {file_name}")#, text)
try:
translated_text = translator.translate(text, dest='en')
#print(f"Translated Text from {file_name}:", translated_text.text)
# create the json file with both original and translated text
results.append({
'file_name': file_name,
'original_text': text,
'translated_text': translated_text.text
})
except Exception as e:
print(f"Translation failed for {file_name} with error: {e}")
else:
print(f"No text found in {file_name} or text is not suitable for translation.")
# Save the json
with open('text_translations2.json', 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=4)
print("All done! The extracted and translated texts are saved in text_translations2.json, maintaining the original order.")
# The process can take up to 30 min
Leveraging Generative AI to Analyze the data¶
Now let's use Gen AI to help us analyzing the data collected.
import json
import os
# Load the JSON file containing the translations
with open('text_translations2.json', 'r', encoding='utf-8') as file:
data = json.load(file)
all_translated_texts = ""
# Loop through each item in the data list
for item in data:
# Append the translated text to the all_translated_texts variable
all_translated_texts += item['translated_text'] + "\n\n"
len(all_translated_texts)
all_translated_texts[:1000]
file_name = data[0]['file_name'] # Adjusted to access the first item in the list
translated_text = data[0]['translated_text']
from openai import OpenAI
os.environ["OPENAI_API_KEY"] = api_key
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4-0125-preview",
max_tokens=4096,
messages=[
{"role": "system", "content": "You are a Cyber Threat Intelligence analyst specialized in China operation. You are dedicated to analyzing leaked sensitive information in relation to Chinese espionage capabilities. The data contains multiple format documents, chat conversion, screenshot of products."},
{"role": "user", "content": f"Make me a summary of this information: {all_translated_texts[:10000]}" }
]
)
print(completion.choices[0].message.content)
Let's modify a little bit our prompt!
file_name = data[0]['file_name'] # Adjusted to access the first item in the list
translated_text = data[0]['translated_text']
from openai import OpenAI
os.environ["OPENAI_API_KEY"] = api_key
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4-0125-preview",
max_tokens=4096,
messages=[
{"role": "system", "content": "You are a Cyber Threat Intelligence analyst specialized in China operation. You are dedicated to analyzing leaked sensitive information in relation to Chinese espionage capabilities. The data contains multiple format documents, chat conversion, screenshot of products..."},
{"role": "user", "content": f"Make me a summary of the following information and include evidences such as names, ip or any other artefacts: {all_translated_texts[:10000]}" }
]
)
print(completion.choices[0].message.content)
Interesting! Now we can get a broader overview of what kind of infomation the data might contains.
Retrieval Augmented Generation (RAG)¶
In that part I want to experiment by using a RAG to load our data.
#!pip install langchain langchain-community chromadb jq
#!pip install langchain-openai
#!pip install jq
#!pip install --upgrade --quiet langchain langchain-openai faiss-cpu tiktoken
Using ChromaDB¶
Let's create a simple RAG using Langchain to be able to query our data based on the question we have.
from langchain.prompts import ChatPromptTemplate
from langchain_community.vectorstores import Chroma, FAISS
from langchain_community.document_loaders import JSONLoader
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Create the embedding
embedding_function = OpenAIEmbeddings()
# Loading our JSON file
loader = JSONLoader(file_path="text_translations2.json", jq_schema=".[] | .translated_text", text_content=False)
documents = loader.load()
db = Chroma.from_documents(documents, embedding_function)
retriever = db.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
query = "Can you give me details about intelligence capabilities from this data leak?"#3"Give me details about the email collection platform"
print(chain.invoke(query))
Using FAISS for RAG with Memory¶
# Uncomment the following line if you need to initialize FAISS with no AVX2 optimization
# os.environ['FAISS_NO_AVX2'] = '1'
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
loader = loader
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1433, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.prompts.prompt import PromptTemplate
retriever = db.as_retriever(search_kwargs={"k":5})
# Define your custom template
custom_template = """YYou are a Cyber Threat Intelligence analyst specialized in China operation. You are dedicated to analyzing leaked sensitive information in relation to Chinese espionage capabilities. The data contains multiple format documents, chat conversion, screenshot of products... If you do not know the answer reply with 'I am sorry'.
Chat History:
{chat_history}
Follow Up Input: {question}
Answer: """
CUSTOM_QUESTION_PROMPT = PromptTemplate.from_template(custom_template)
# Initialize memory for chat history
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# Initialize the ConversationalRetrievalChain
qa_chain = ConversationalRetrievalChain.from_llm(model, retriever, condense_question_prompt=CUSTOM_QUESTION_PROMPT, memory=memory)
def execute_conversation(question):
# Load conversational history from file
try:
with open('conversational_history.json', 'r') as f:
conversational_history = json.load(f)
except FileNotFoundError:
conversational_history = []
# Update conversational history with the user's question
conversational_history.append(("User", question))
# Use the ConversationalRetrievalChain to get the answer
result = qa_chain({"question": question})
# Extract the 'answer' part from the result
response_text = result.get('answer', 'Sorry, I could not generate a response.')
# Update conversational history with the bot's response
conversational_history.append(("Bot", response_text))
# Limit the history to the last 10 turns
if len(conversational_history) > 10:
conversational_history = conversational_history[-10:]
# Save conversational history to file
with open('conversational_history.json', 'w') as f:
json.dump(conversational_history, f)
# Save conversational history to file
with open('conversational_history.json', 'w') as f:
json.dump(conversational_history, f)
# Print only the last message in the conversational history
last_message = conversational_history[-1]
print(f"Discussion:\n{last_message[0]}: {last_message[1]}")
# Call the function with a question
execute_conversation("WHich countries might be a target according to the documents?")
# Call the function with a question
execute_conversation("Give me more details about any references related to espionage capabilities")
# Call the function with a question
execute_conversation("Give me more details about the email/social network intelligence platform")
# Call the function with a question
execute_conversation("Extract and summarize any kind of information that might be useful for a defender or a threat analyst, including potential IOCs and TTPs")
What next?¶
In this document, we explored a method to analyze data in PNG format and in the Chinese language, concerning a leak related to a government contractor with offensive capabilities. We demonstrated how to leverage OCR to extract data from the PNG files and translate them into English to glean more details about it. Then, we used generative AI to summarize some of the information available and finally created a RAG to enable the exploration of and specific data requests without manually digging through the vast amount of information.
There is obviously more to discover, and I hope this process will assist you in further analyzing the data leak.
If you like this notebook, stay tuned for more soon!
Thomas Roccia | @fr0gger_